COLMAP 3.x Pipeline — Detailed
All commands and workflows here are COLMAP 3.x. COLMAP 4 is in active development with improved feature matching, better GPU acceleration, and a modernised architecture — worth watching, but our current pipelines rely on COLMAP 3.x which is battle-tested and widely supported.
per image
+ RANSAC filtering
Full SfM → estimate
optimisation
+ poses
SIFT keypoint detection and descriptor extraction from every image. The keypoints are what COLMAP matches across images.
Exhaustive matching for dome captures (every image vs every other). Sequential matching for video. COLMAP internally runs RANSAC to filter outlier matches geometrically. Exhaustive matching is O(n²) — for 200 images that is 19,900 pairs; for 500 images it is 124,750 pairs. This is why matching can take several hours for large real-world captures. For drone datasets with thousands of images, consider sequential or vocabulary-tree matching to keep matching tractable.
CG pipeline: known poses → point_triangulator only. Fast, because pose estimation is skipped — COLMAP simply projects rays from the known camera positions and finds where they intersect. Real-world pipeline: incremental SfM — COLMAP estimates poses from scratch, one image at a time, growing from a seed pair. Slower and more sensitive to bad input, but handles the uncertainty inherent in real captures.
The most computationally expensive step — and also where the most quality is gained. Bundle adjustment jointly optimises ALL camera poses and ALL 3D point positions simultaneously, minimising total reprojection error across every image at once. This is a large sparse non-linear least-squares problem. For 500 images it can involve millions of variables. Only needed in full SfM mode; when poses are already known (CG pipeline), it is skipped entirely.
COLMAP 3.x — manual PowerShell commands (use when the .bat fails):
# 1. Feature extraction — note camera model params colmap feature_extractor ` --database_path .\database.db ` --image_path .\images ` --ImageReader.camera_model PINHOLE ` --ImageReader.single_camera 1 ` --ImageReader.camera_params "3200.5,3200.5,1920,1080"
# 2. Exhaustive matching (for dome captures) colmap exhaustive_matcher ` --database_path .\database.db
# 3. Triangulation from known poses colmap point_triangulator ` --database_path .\database.db ` --image_path .\images ` --input_path .\sparse\0 ` --output_path .\triangulated
# 4. Inspect result (optional) colmap gui ` --database_path .\database.db ` --image_path .\images ` --import_path .\triangulated
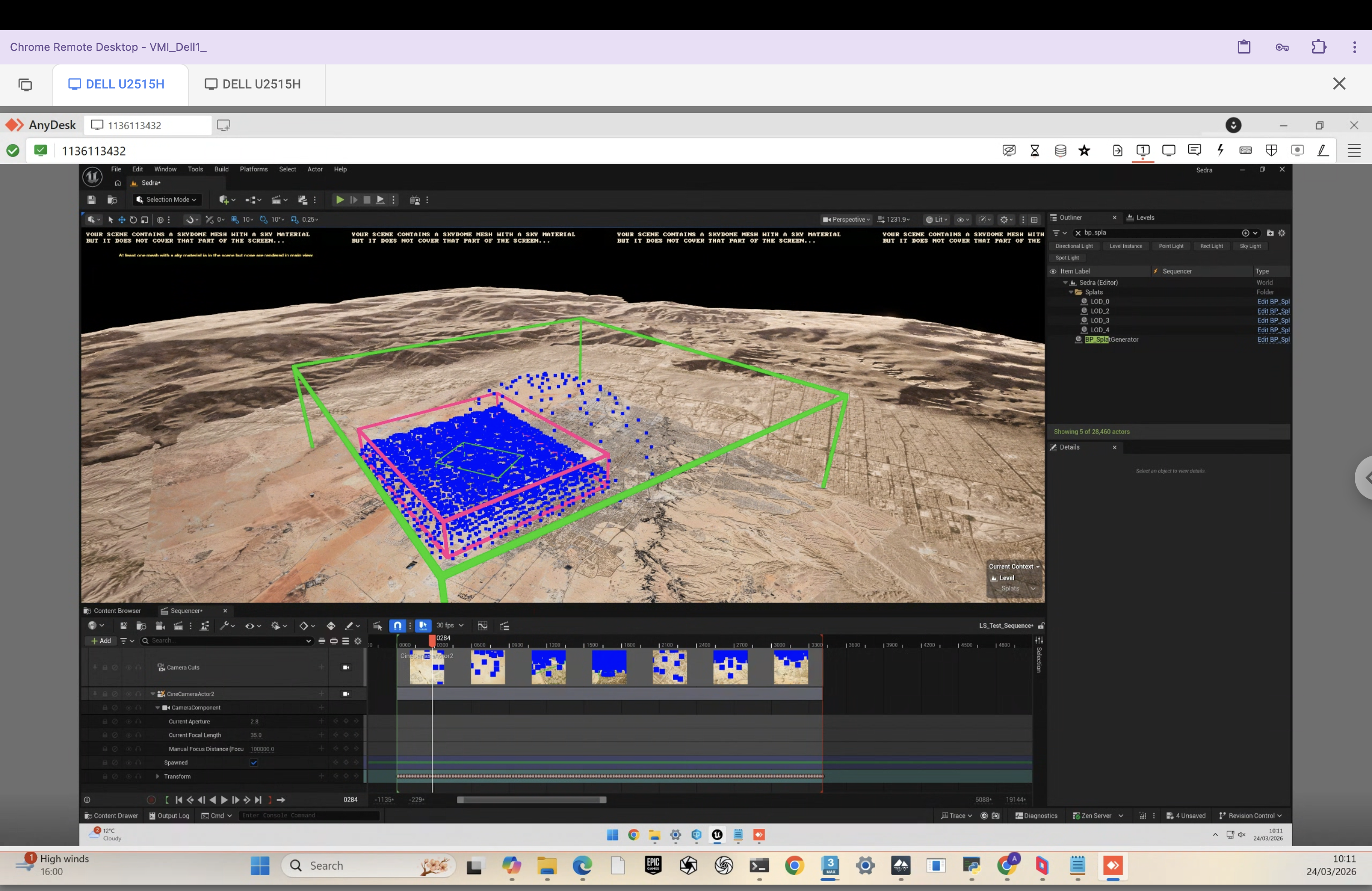
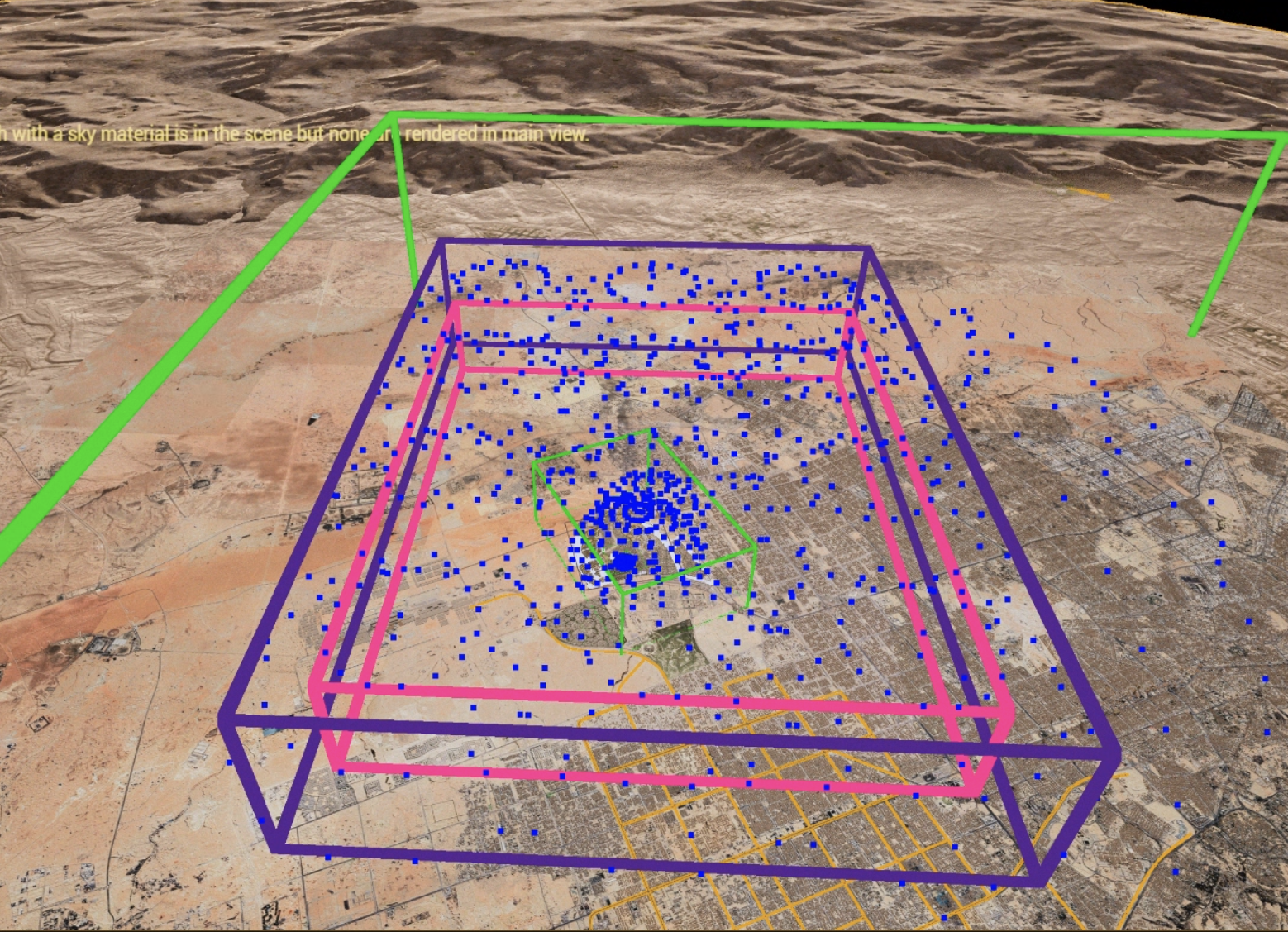
COLMAP — dome camera distribution with projection rays + aerial render
COLMAP 4 — What's New
COLMAP 4 is a significant upgrade over 3.x. Our pipelines currently use 3.x, but 4 is worth migrating to:
Replaces SIFT with a learned feature detector. More robust on textureless surfaces, repetitive patterns, and challenging lighting. Fewer failed registrations.
Global SfM instead of incremental. Registers all images simultaneously rather than one at a time. Significantly faster on large datasets and more robust to weak connectivity.
Feature extraction and matching run faster on GPU. Matching 500+ image datasets that took hours in 3.x can finish in minutes.
Neural matcher that replaces brute-force nearest-neighbor. Handles viewpoint changes and lighting variation much better than traditional descriptor matching.
Migration path: our batch GUI already detects COLMAP version and unlocks v4 features automatically. The COLMAP format (cameras.txt, images.txt) is unchanged — downstream pipeline stays the same.